Gradium #1 on Coval TTS Benchmarks

In natural conversation, the gap between one person finishing a sentence and the other starting to respond averages around 200 milliseconds.
For voice agents built on cascaded pipelines (STT, LLM, tool calls, TTS), TTS is the last stage before the user hears anything, and it inherits every upstream delay.
The latency budget for TTS itself is typically 200-300ms Time to First Audio (TTFA).
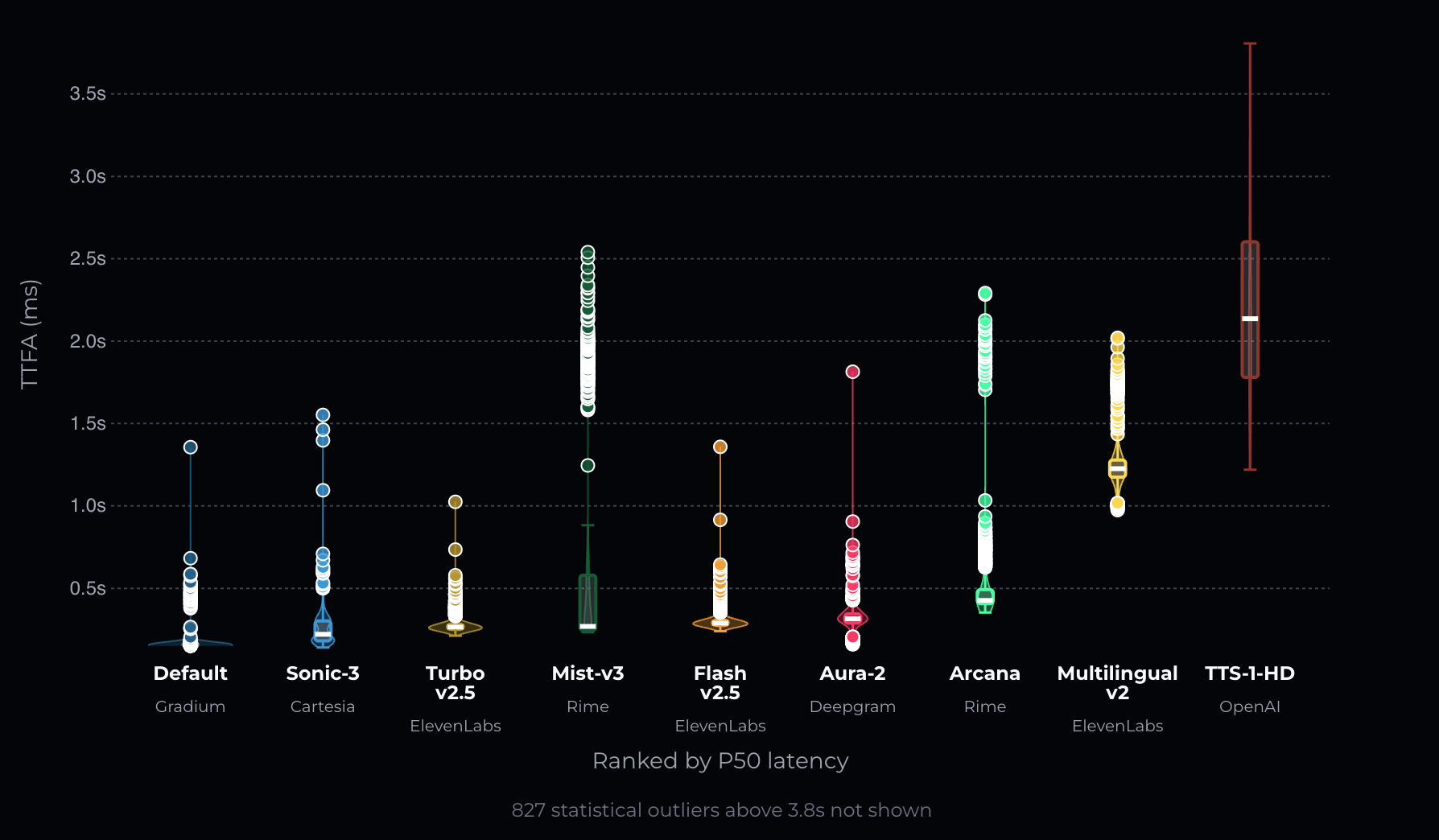
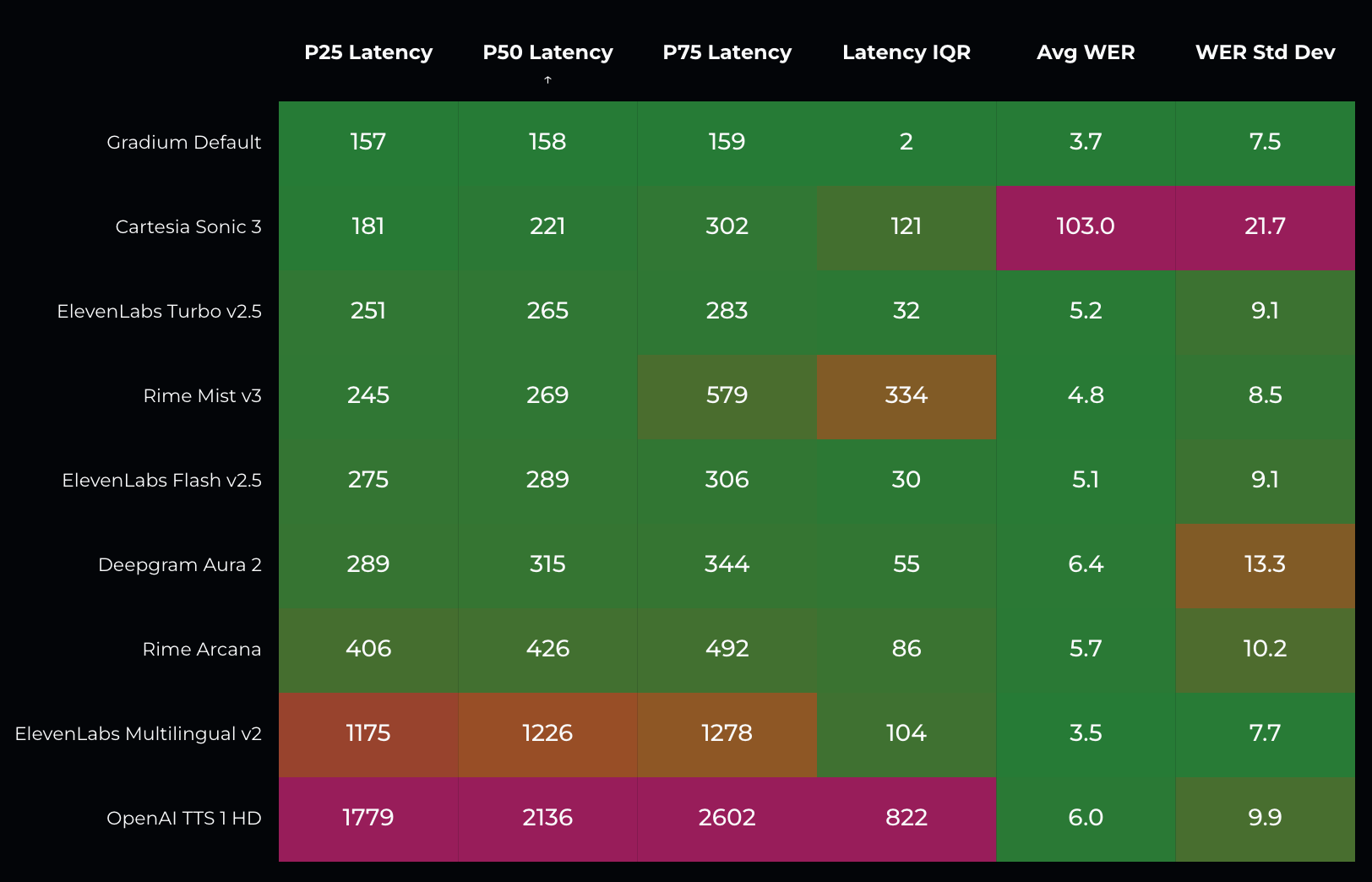
As of May 13, 2026, Gradium ranks first on Coval's TTS benchmarks across all latency metrics: P50 TTFA, latency range (P25-P75 spread). This is not at the expense of quality metrics: Gradium provides state of the art Word Error Rate (WER).
Coval is an independent voice AI evaluation platform (YC S24); its TTS benchmark results are published at benchmarks.coval.ai/tts. Gradium develops audio language models that power text-to-speech, speech-to-text, and voice cloning through a single API. This post covers the methodology and the results of Gradium, ElevenLabs flash_v2.5 and Multilingual v2, Cartesia sonic-3, Rime arcana, and OpenAI.
What Coval is and why its TTS benchmarks matter
Coval was founded in 2024 by Brooke Hopkins, who previously built evaluation job infrastructure for self-driving at Waymo. The platform applies the testing rigor self-driving teams developed over a decade (simulation-driven testing, continuous benchmarking, trajectory-based analysis) to voice and chat AI evaluation.
Most TTS benchmarks come from the vendors themselves. The conditions get picked to flatter the system being measured: studio-quality reference text, simple inputs, controlled load, P50 numbers without spread. The measurements are real, but they are not comparable across providers, and they do not necessarily reflect production conditions.
Coval's approach is the opposite: standardized conditions across providers, continuously updated, with methodology, and code made public. For voice agent teams, this is the closest thing the industry has to an apples-to-apples TTS comparison.
What Coval measures today: TTFA, latency range, and TTS WER
The TTS suite measures three properties that determine whether a voice agent works in production.
Time to First Audio (TTFA) is the time from when a request is sent to until the first streamed chunk containing audio samples is received from the API. TTFA is reported at P50, P75, P95, and P99. For deeper methodology, see Time to First Audio: Measuring and Reducing TTS Latency in Voice Agents.
Latency range is the P25-P75 spread of TTFA across requests. Conversational latency is governed by both the worst case and the median. A model with 200ms P50 and 600ms P75 will feel worse than one with 250ms P50 and 300ms P75.
Word Error Rate (WER) for TTS is an intelligibility metric. The synthesized audio is transcribed with a reference STT model and the resulting transcript is compared to the input text. Low WER means the model articulates correctly, handles complex pronunciations cleanly, and does not hallucinate or drop words. WER on TTS is distinct from WER on STT, which measures transcription accuracy on real human speech.
TTS benchmark results: Gradium vs. ElevenLabs, Cartesia, Rime, and OpenAI
Gradium ranks first overall, as of May 13th, 2026. That means that the Gradium model is SOTA on all measurable metrics, consistent with their mission to provide low latency voice models that scale.
Methodology: Coval's benchmark methodology and code are open source at github.com/coval-ai/benchmarks. The full input dataset is published and covers the kinds of utterances voice agents handle in production. Two examples:
"There's a slight delay with your $347.89 order, but we expect it to ship by Friday afternoon."
"Hi Ms. Garcia, your appointment with Dr. Peterson is scheduled for Tuesday, March 5th at 10:30 AM."
Why Gradium ranks first on Coval's TTS benchmarks
Gradium develops audio language models (ALMs), an audio-native counterpart to LLMs. Rather than training a TTS model and stitching it into a pipeline with bespoke tuning, an ALM is trained on paired audio and text and performs multiple voice tasks within a single architecture. This paradigm was originally introduced by Gradium's founders at Google and Meta and has since become the dominant approach across the industry. Gradium's models are based on Delayed Streams Modeling (DSM, arXiv:2509.08753), which enables batched generation while preserving streaming capabilities.
For more details, see Optimizing Quality vs. Latency in Real-Time TTS.
How to reproduce Coval's TTS benchmarks
Coval's benchmark code is open source: github.com/coval-ai/benchmarks. The suite can be run against any combination of providers, with custom audio data and test scenarios.
For voice agent teams, this is more useful than relying on either vendor-reported numbers or generic public results. Production conditions are specific to your text inputs, your latency budget, your concurrent load.
What Coval's public TTS benchmark doesn't (yet) cover
The public Coval suite covers latency, consistency, and intelligibility. At the moment, it does not yet include:
- Languages beyond English. Our internal benchmarks show consistent performance for WER across languages: see The most accurate multilingual text-to-speech, by the numbers.
- Voice cloning fidelity. Also benchmarked on the Gradium blog with blind ELO across four languages: Why Your Voice Cloning Sounds Fake (And How to Fix It).
Get started with Gradium TTS and Coval
If you're building a voice agent and want to talk through TTS evaluation, benchmarking methodology, or how Gradium fits into your stack, we'd love to hear from you. Reach out at contact@gradium.ai or visit gradium.ai.
You can also start integrating Gradium right away: Get started.
To run your own TTS evaluations: benchmarks.coval.ai/tts for live results, github.com/coval-ai/benchmarks for the code. For partnership and enterprise enquiries, contact Coval at sales@coval.dev.
References
- Gradium, Optimizing Quality vs. Latency in Real-Time TTS AI Models.
- Gradium, Why Your Voice Cloning Sounds Fake (And How to Fix It).
- Gradium API documentation, pronunciation dictionaries: gradium.ai/api_docs.html.
- Coval voice AI benchmarks: benchmarks.coval.ai. Methodology and code: github.com/coval-ai/benchmarks.