

Why Your Voice Cloning Sounds Fake (And How to Fix It)
Which voice sounds more like the original?
Voice cloning technology has evolved beyond simple text-to-speech (TTS) synthesis. Modern AI voice cloning requires authentic preservation of speaker identity, creating personalized voices that sound genuinely human across different contexts, languages, and use cases.
Personalized news delivery requires a polished, radiophonic quality with professional gravitas and clear enunciation. Customer care applications need semi-professional voices that balance competence with approachability and warmth, voices that sound helpful rather than robotic. Video games and entertainment require expressive, even cartoonish character voices with exaggerated emotional range and personality. Each use case has unique requirements, and authentic voice cloning must preserve the specific vocal characteristics that make each style work in its context, in particular for real-time voice synthesis.
At Gradium, our Instant Cloning technology delivers real-time voices with the best speaker similarity, based on thousands of blinded human evaluations.
Developers, creators, and product managers can generate custom voices at scale very quickly, while maintaining the unique characteristics that make each voice instantly recognizable.
Benchmark Overview
We designed this benchmark to be falsifiable, repeatable, and grounded in human perception, not marketing demos.
The evaluation covered English, French, Spanish, and German. Because Gradium focuses on real-time voice AI applications, we compared our Instant Voice Cloning technology with the ElevenLabs Flash model.
We created a test set of 890 sentences per language, with different complexity, from level 1 sentences: simple conversational questions and common interactions, to level 3 sentences: complex numbers, URLs, emails, addresses, and rare named entities. Sentences are of various length.
- Level 1 example: I have an opening at 3:00 PM.
- Level 3 example: Your onomatopoeic description of the sound is helpful, but I need the alphanumeric error code e.g., 0x80070057 to diagnose the bugcheck.
The content reflects real-world use cases, including customer support, media production, gaming, and creative industries.
For each language, we selected 20 unique voices and generated all sentences using instant voice cloning with only 10 seconds of source audio.
The voices represented diverse characteristics:
- Accents and regional variations
- Perceived genders and age ranges
- Speaking styles and prosody
Human evaluators conducted blinded A/B listening tests, comparing anonymized voice clones with the original recordings. Evaluators chose the voice that sounded closest to the original.
Each comparison updated a live Elo ranking system, allowing us to measure voice identity fidelity over time. In total, 3220 voice pairs were evaluated.
Gradium achieved the highest Elo scores in all evaluated languages.
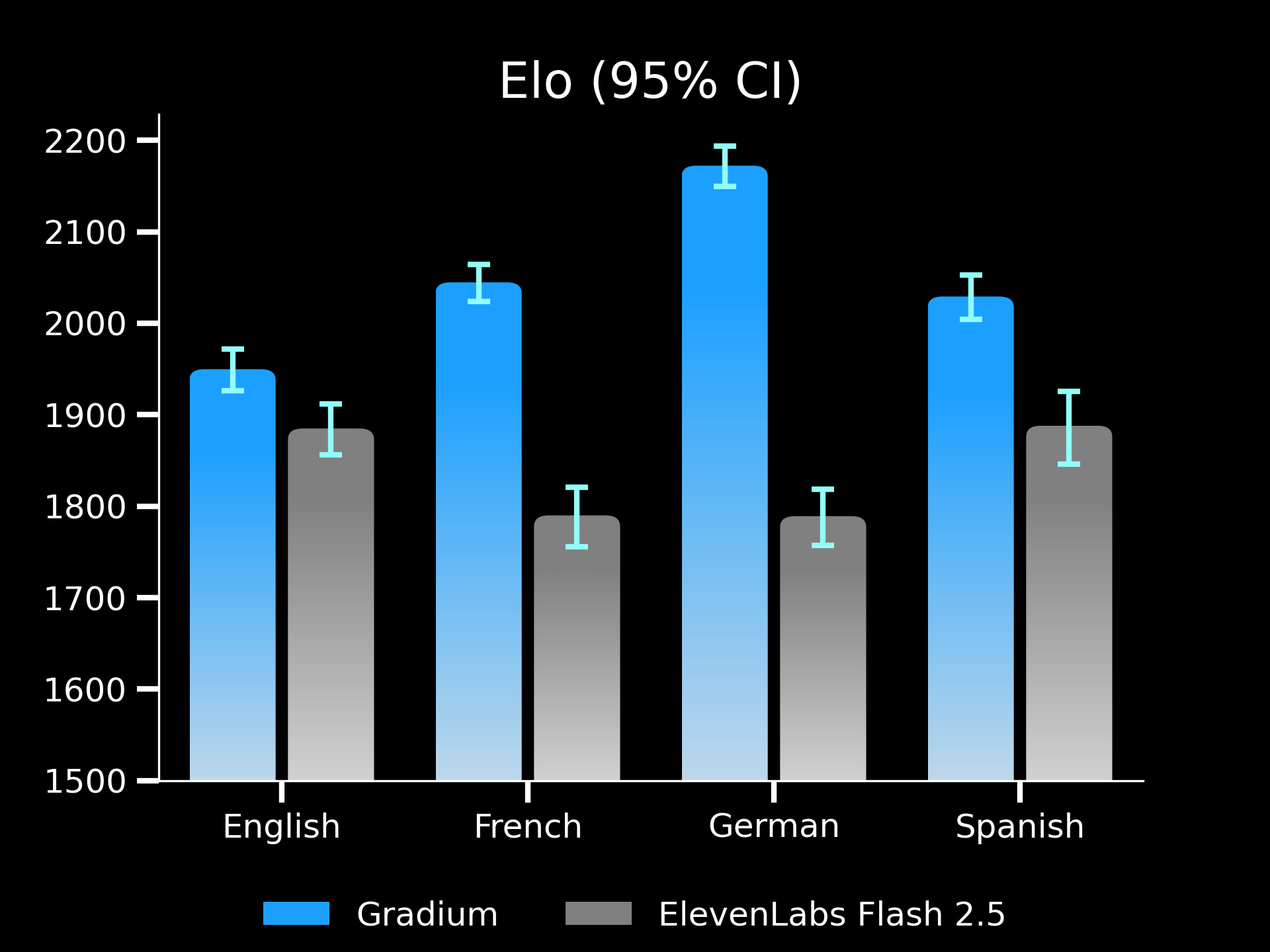
Models optimized solely for latency often compress voice identity cues. Gradium retains micro-traits such as vocal fry, rasp, breathiness, and pitch dynamics, even when switching languages or scripts.
This ensures consistent, high-quality personalized voices that maintain the original speaker’s character in any context.
How Voice Cloning Technology Works: The Technical Foundation
Voice cloning AI can be implemented through several architectural approaches. Understanding these methods helps explain why some solutions preserve voice identity better than others.
Common Approach: Prefixing Method
A popular voice cloning technique uses "prefixing": the AI model processes the voice sample as if it has already generated that audio, treating the new text as a continuation.
Advantages:
- No special training requirements
Disadvantages:
- Typically requires transcripts for the audio recording
- Source audio must be cleanly trimmed to avoid glitches
- Limited flexibility in voice adaptation
Gradium's Approach: Integrated Voice Cloning Architecture
Gradium integrates voice cloning from the ground up using cross-attention layers that attend to speaker recordings during training. This architecture gives the model greater freedom to respect speaker identity while generating text, without treating output as a direct continuation of the voice sample.
Classifier-Free Guidance: Controlling Voice Similarity
A critical tool for balancing voice fidelity with generation quality is the Classifier-Free Guidance (CFG) scale α, introduced by Jonathan Ho and Tim Salimans.
The CFG mechanism modifies the model's predicted output distribution:
Where O(text, ∅) represents the predicted distribution without voice cloning information.
- α = 1: Standard model output
- α = 0: Voice cloning completely ignored
- α between 0-1: Interpolation between baseline and voice-cloned output
- α > 1: Extrapolation that amplifies voice characteristics
When α exceeds 1, the system extrapolates beyond standard voice cloning, moving away from the baseline and emphasizing distinctive speaker traits. This operates in log-probability space, and while mathematically complex, it produces remarkably authentic results.
However, extreme values can over-amplify characteristics like hesitations or background sounds. Gradium exposes this as the "Voice Similarity" parameter in our playground, allowing users to balance maximum fidelity with the model's adaptive flexibility. Try it yourself with the slider below.
Try adjusting the Classifier-Free-Guidance α
Why Voice Identity Matters for AI Voice Applications
When an AI voice maintains consistent identity across interactions, users experience continuity instead of subtle confusion. Preserving vocal micro-traits creates trustworthy interactions, especially critical for live voice AI applications and real-time conversational AI.
For products relying on long-term user relationships—from virtual assistants to customer service bots—our customers report that identity consistency isn't optional. It's fundamental to user trust and engagement with voice AI technology.
Key Benefits of Gradium Voice Cloning:
- Speed: From recording to production-ready voice in seconds
- Ease of Use: Simple integration via AI voice API or studio interface
- Reliability: Consistent speaker identity across languages, scripts, and contexts
- Scale: Rapid iteration and personalized voice generation for enterprise needs
- Flexibility: Create voices with diverse accents, ages, genders, and speaking styles
- Brand Alignment: Match voices to specific brand identities and tones
- Multi-Platform: Deploy high-quality, unique AI voices across applications and platforms
Watch our CEO Neil experiment with a live demo in front of thousands of people with multiple instant voice cloning examples
Try Gradium Voice Cloning yourself
Creating a new voice with Gradium is simple.
- Record as little as 10 seconds of audio
- Gradium analyzes voice identity within a few seconds
- Generate speech via our AI voice API or studio
With our XS plan and above, you can generate up to 1,000 voice clones, with unlimited scaling on enterprise plans. With our free tier (no credit card required!) you can also start real-time voice cloning with the Gradium Voice API in a few seconds: get started here.