Optimizing Quality vs. Latency in Real-Time Text-to-Speech AI Models

At Gradium, we develop cutting-edge audio language models designed to deliver natural, expressive, ultra-low latency voice interactions at scale and capable of performing any voice task from voice cloning to conversational AI. We provide access to text-to-speech (TTS) and speech-to-text (STT) models through our API, and the models can run on a variety of NVIDIA GPUs, from L4 to H100, enabling flexible deployment to match diverse performance and scalability needs.
Streaming Audio Models for Real-Time Voice Applications
As these models are used to build real-time voice agents, the two most important performance metrics are:
- Time To First Audio (TTFA): the time it takes from a user initiating a connection to the API to receiving the first meaningful audio packet.
- Real-time factor (RTF): how much faster than real-time audio gets generated. A RTF of 2x means that it takes 0.5s to generate one second of audio.
For interactive voice AI applications, it is important for the real-time factor to be above 1 so that there is no audio skip. A higher RTF is useful for applications where lookahead on audio outputs is needed to control another model, for example generative lipsync. As for the time-to-first- audio, it should be as small as possible, with 300 milliseconds being a good target to ensure that AI voice agents answer their users quickly.
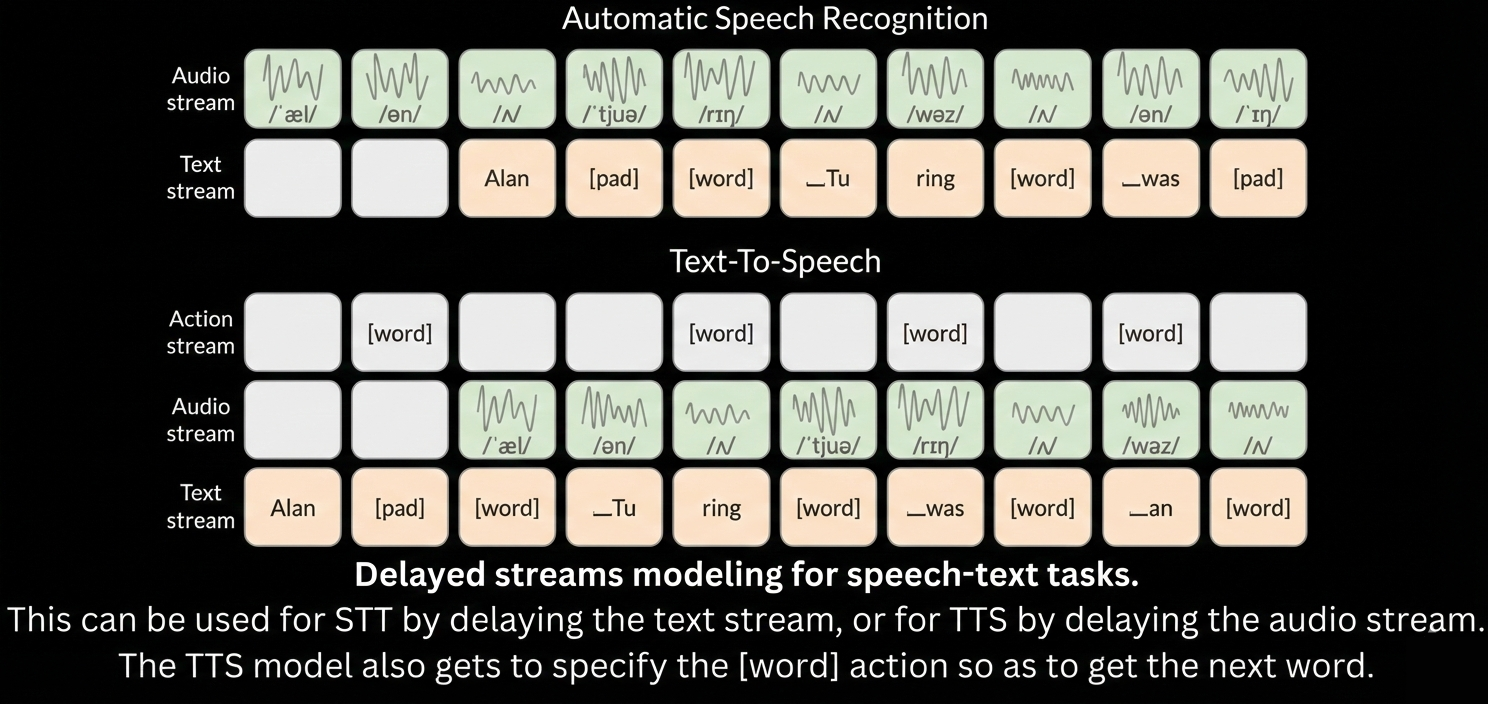
Additionally, all our models are streaming so that for a text-to-speech model it is possible to give it its input one word at a time and get a stream of resulting audio. This is especially helpful when the audio gets generated for the output of a text LLM as these models generate their outputs one word at a time, so the overall latency is as good as possible. We developed an extensive performance benchmark harness to conduct stress tests on our systems and evaluate them under real-world conditions.
Delayed Streams Modeling Model Architecture
Our models are based on the Delayed Streams Modeling (DSM) architecture as introduced in this arxiv paper. The main benefit of this architecture is to enable batching generation while preserving the streaming capacities of the models, ensuring that latency is as low as possible.
A key aspect of these models is audio tokenization, the audio signal is represented as discrete tokens using Residual Vector Quantization (RVQ). For each time-slice of typically 80ms, the audio is represented as up to 32 audio tokens coming from the same number of codebooks. The residual aspects means that the first codebook handles most of the signal, the second codebook most of the remaining signal etc, so it’s possible to use fewer than 32 codebooks in a setting where a lower quality is acceptable, with more codebooks representing a higher audio bitrate.
Another benefit of the DSM approach is to use the same architecture for text-to-speech and speech-to-text models. Models combine text streams and audio streams, some of them being delayed over time. A TTS model takes an input text stream and generates a delayed audio stream. A STT model takes as input an audio stream and generates a delayed text stream.
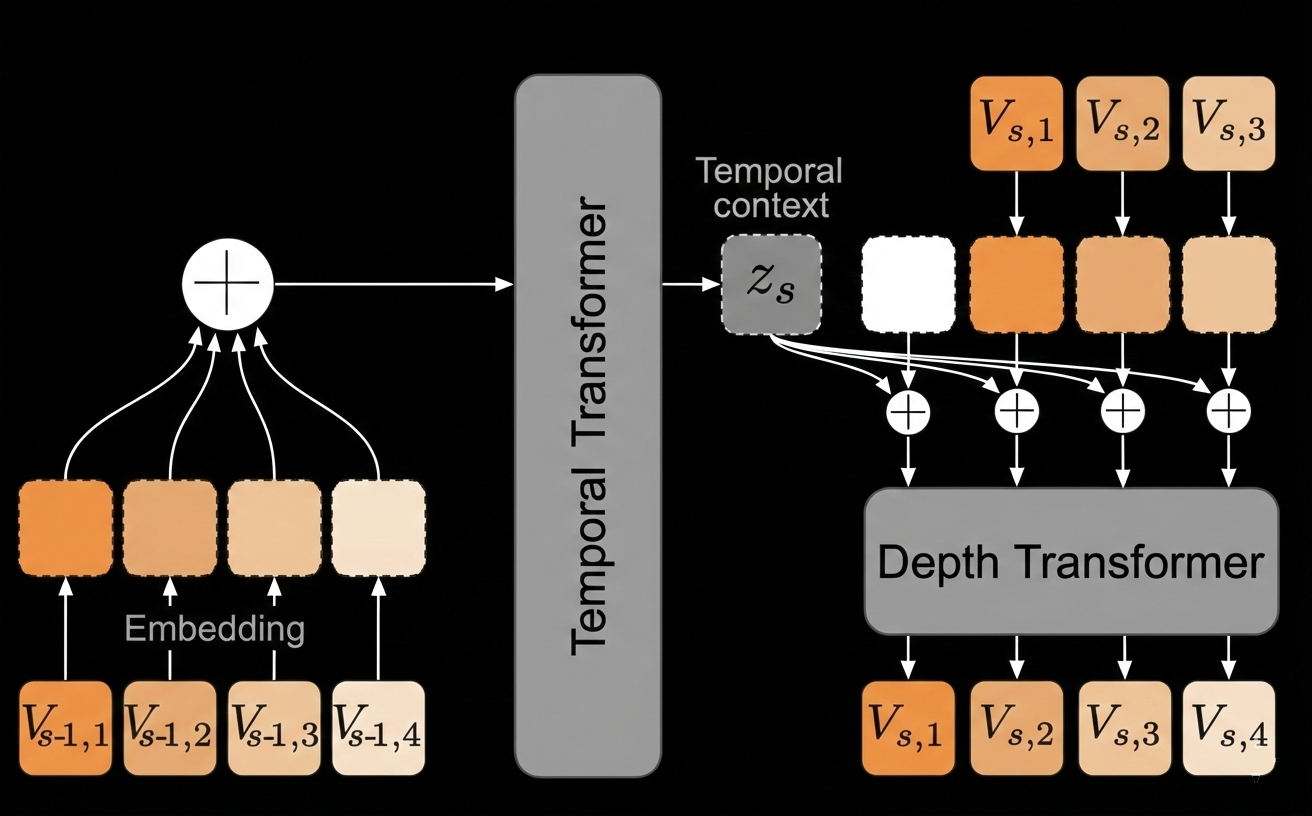
The DSM architecture involves a RQ-transformer as introduced in the moshi paper. This is composed of a temporal transformer backbone coupled with a smaller depth transformer used to generate each codebook.
Optimizing our Text-To-Speech Models on NVIDIA Hardware
Low latency audio models tend to be fairly small compared to text or multi-modal LLMs. These models tend to have on the order of hundreds of millions to billions of parameters rather than hundreds of billions for frontier models. This implies different tradeoffs when running inference at scale. As a member of the NVIDIA Inception program, Gradium stays close to the latest GPU architectures and CUDA features, which we use to push these models to lower latency and more efficient inference on NVIDIA hardware. The operations involved in the model are small enough so that there is some significant overhead to launching the CUDA kernels compared to the time that the kernels actually run on the GPU. There are multiple ways to get around this:
- Fusing kernels to reduce their total numbers using torch.compile or the Triton compiler.
- Using the CUDA Graph API reduces the overhead of scheduling the kernels. A CUDA graph stores all the kernels to be launched for a forward step. Replaying the graph is then very fast as all the necessary machinery is already in place.
We rely heavily on both techniques. In order to show the impact of using CUDA graphs, we ran one of our text-to-speech models with and without enabling the CUDA graph functionality. The benchmark ran for various batch sizes. Measurements are done on an NVIDIA RTX 4080 Super, and we report all TTFA numbers in milliseconds.
CUDA Graph Enabled
| Batch Size | TTFA p50 | TTFA p90 | TTFA max | RTF p50 | RTF p90 | RTF max |
|---|---|---|---|---|---|---|
| 8 | 220.7 | 228.4 | 229.8 | 4.39 | 4.43 | 4.47 |
| 16 | 258.5 | 266.3 | 272.7 | 3.80 | 3.87 | 3.95 |
| 24 | 274.4 | 289.9 | 300.0 | 3.52 | 3.63 | 3.70 |
| 32 | 310.6 | 326.3 | 334.4 | 3.15 | 3.28 | 3.40 |
| 48 | 376.6 | 395.1 | 405.8 | 2.67 | 2.82 | 2.89 |
| 64 | 431.7 | 454.9 | 471.0 | 2.25 | 2.42 | 2.55 |
CUDA Graph Disabled
| Batch Size | TTFA p50 | TTFA p90 | TTFA max | RTF p50 | RTF p90 | RTF max |
|---|---|---|---|---|---|---|
| 8 | 562.4 | 585.4 | 1488.3 | 1.51 | 1.52 | 1.53 |
| 16 | 573.9 | 597.1 | 621.3 | 1.47 | 1.48 | 1.49 |
| 24 | 574.5 | 616.7 | 679.7 | 1.43 | 1.46 | 1.48 |
| 32 | 588.8 | 621.0 | 875.6 | 1.40 | 1.43 | 1.45 |
| 48 | 640.0 | 680.2 | 845.1 | 1.29 | 1.34 | 1.37 |
| 64 | 684.5 | 732.6 | 888.7 | 1.23 | 1.27 | 1.31 |
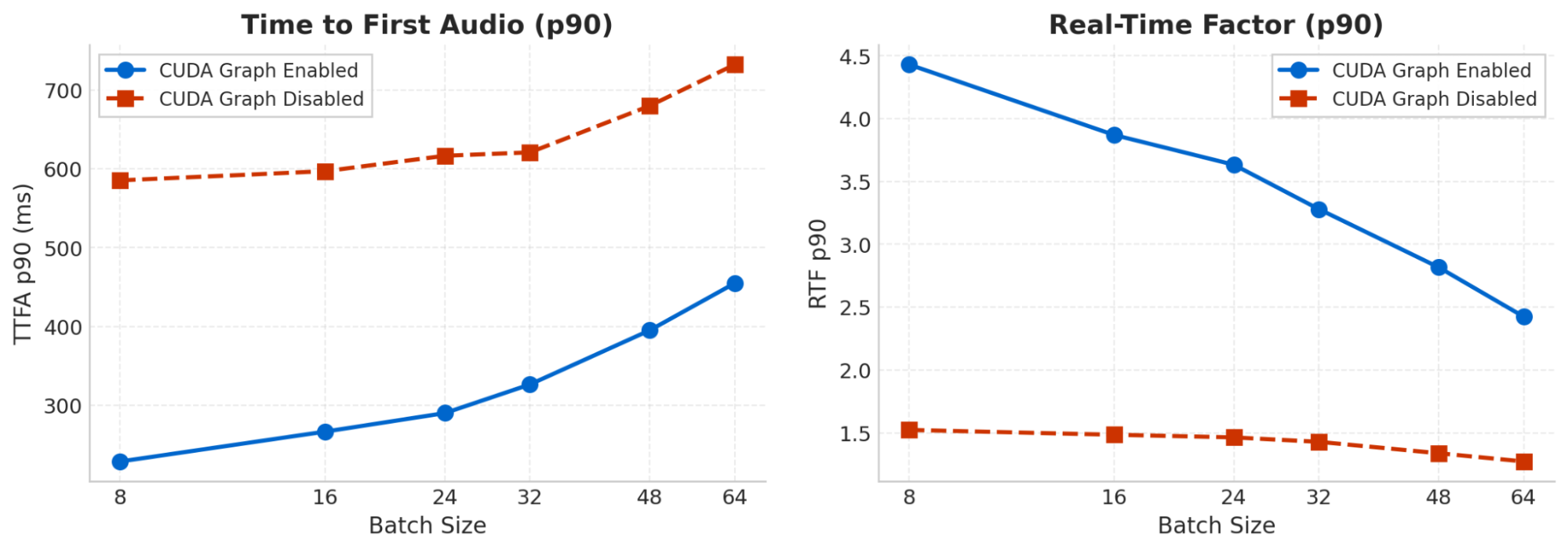
As expected the improvement is larger for smaller batch sizes as the kernel launch overhead is proportionally larger.
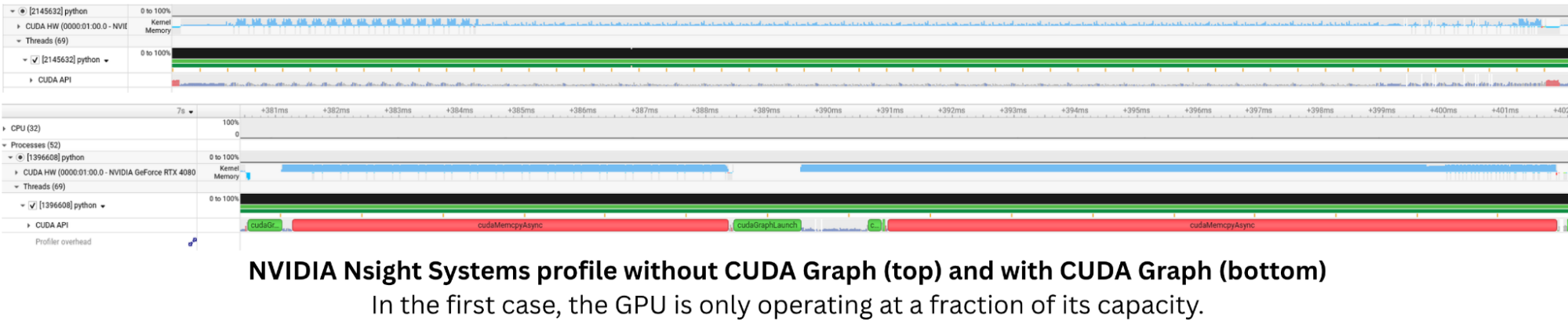
We can confirm this by looking at the CUDA profiling generated using NVIDIA Nsight Systems. The profile below shows the execution of the model with and without CUDA Graph enabled. With CUDA Graph enabled the kernels are launched in a very tight sequence, without any significant gap between them, which is what allows us to achieve such low latency.
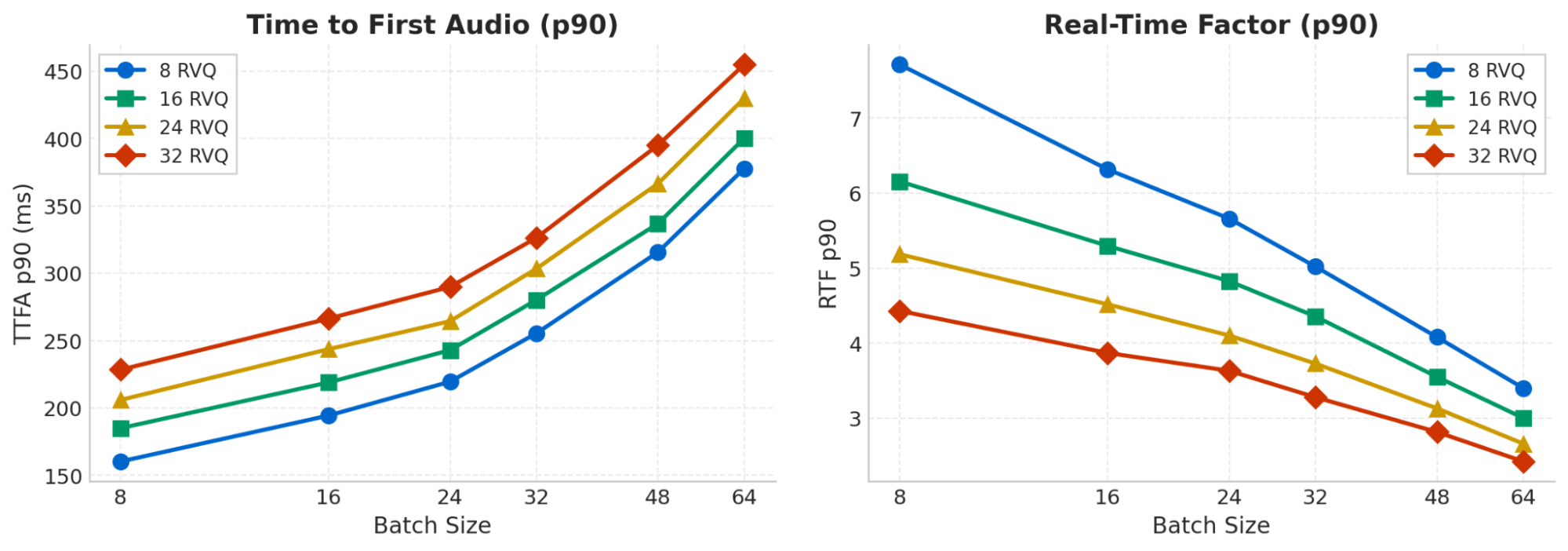
Reducing the Number of Generated Codebooks
We train our text-to-speech models in such a way that it is possible at inference time to decide on the number of codebooks to be generated. This makes it possible to pick the best tradeoff between audio quality (better with a larger number of codebooks), latency (faster with a smaller number of codebooks), and GPU costs.
We ran benchmarks for the same model with various numbers of codebooks generated, from 8 to 32. This time again, measurements are done on an NVIDIA RTX 4080 Super, all TTFA numbers are given in milliseconds and are for the p90 percentile.
| Batch Size | TTFA 8 | RTF 8 | TTFA 16 | RTF 16 | TTFA 24 | RTF 24 | TTFA 32 | RTF 32 |
|---|---|---|---|---|---|---|---|---|
| 8 | 160.3 | 7.71 | 185.0 | 6.16 | 206.0 | 5.19 | 228.4 | 4.43 |
| 16 | 194.4 | 6.32 | 218.9 | 5.30 | 243.6 | 4.52 | 266.3 | 3.87 |
| 24 | 219.5 | 5.66 | 242.9 | 4.83 | 264.4 | 4.10 | 289.9 | 3.63 |
| 32 | 255.4 | 5.02 | 280.2 | 4.36 | 303.4 | 3.73 | 326.3 | 3.28 |
| 48 | 315.7 | 4.08 | 336.8 | 3.55 | 366.5 | 3.13 | 395.1 | 2.82 |
| 64 | 377.7 | 3.40 | 400.2 | 3.00 | 429.8 | 2.66 | 454.9 | 2.42 |
Empowering the Next Generation of Voice AI Agents
These performance optimizations translate directly into significant business value for companies building voice AI agents and conversational platforms. By achieving a lower time-to-first-audio and maintaining real-time factors above 2x even at scale, voice AI applications can deliver conversational experiences that feel natural and responsive, even when deploying customer service AI agents that handle thousands of concurrent calls. For large-scale voice AI deployments, our streaming architecture eliminates the awkward pauses that plague traditional TTS systems, reducing user frustration, abandonment rates and costs. Companies leveraging these optimizations report improved customer satisfaction scores, higher engagement rates compared to legacy speech synthesis solutions. As conversational AI becomes increasingly central to customer experience strategies, the latency and quality trade-offs we've optimized enable voice agents that users actually want to interact with, turning what was once a frustrating technology into a competitive advantage for our users. You can try out our models at gradium.ai.