

The most accurate multilingual text-to-speech, by the numbers
As we ship and improve our text-to-speech models, it is important to measure one key aspect of such models: pronunciation accuracy. Our system should pronounce exactly what is input by the user. How this is typically done in research work is by first transcribing the produced audio and comparing this transcript to the original text input.
Normalization
There exists no one-to-one mapping between a text and the corresponding speech. Many texts exist that could map to the same speech audio. One way to alleviate the problem is to try and normalize both the input and transcribed text. For instance, converting to lowercase, removing punctuation, converting numbers to an all-digit form...
A popular option is to use the Whisper English normalizer. Extending it to other languages can be challenging though, requiring fine linguistic knowledge. The parsing itself can be daunting. Parsing tools such as parser combinators can come to the rescue, such as with Kyutai's tts_longeval French normalizer.
That said, even a clean parser-combinator design hits a ceiling. Some of the things that are hard or genuinely impossible to handle robustly:
- Homophones. In many languages, two forms differ only in writing: orally they are indistinguishable. There is no principled way to pick one without semantic context. In French for instance, imperative and infinitive forms for verbs are pronounced the same.
- Complex numbers and serials. Long numbers, dates with mixed formats, license plates, social security numbers, phone numbers. Should all numbers and letters be glued together? Should they be space, comma or hyphen separated?
Here is a visualization of the normalization process on a simple text input:
Measuring Word Error Rate
Word error rate (WER) measures the minimum number of operations needed to transform the transcript of the generated audio into the input reference text. The operations are: insertions (a word in the transcript is not in the input), deletions (a word in the input is not in the transcript), and substitutions (a word was replaced by another one). This is estimated through dynamic programming, typically with the jiwer package. Given the number of insertions , deletions , substitutions , and the number of words in the reference text, the WER is defined as
Benchmark setup
We report WER on the MiniMax Multilingual TTS Test Set, a public benchmark used in a number of recent TTS papers, which makes our numbers directly comparable to existing work.
For ASR we use Qwen3-ASR, and for normalization we use:
- The Whisper English normalizer for English.
- The kyutai/tts_longeval French normalizer for French.
- The Whisper basic normalizer for Spanish, Portuguese, and German.
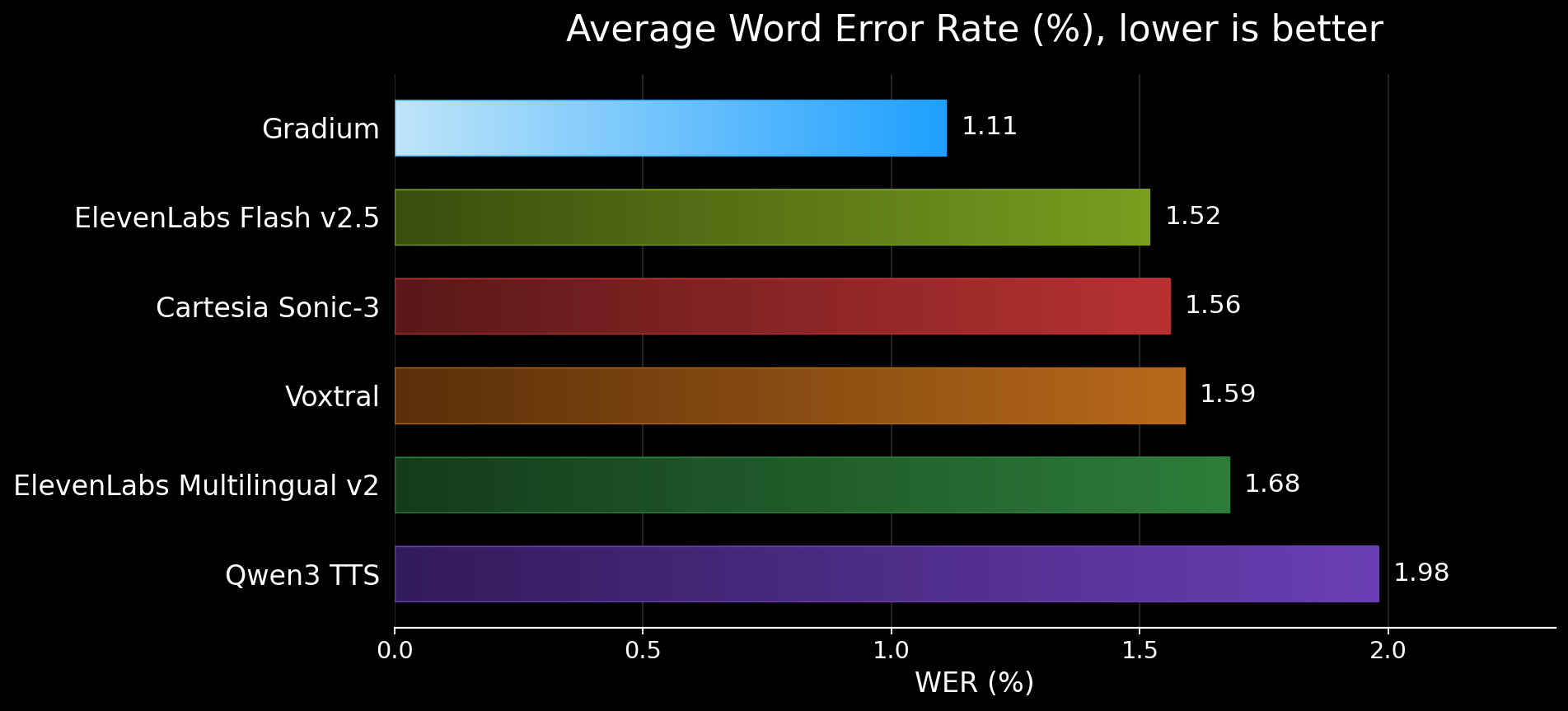
Results
WER (%) on MiniMax Multilingual, lower is better. Best per language in bold.
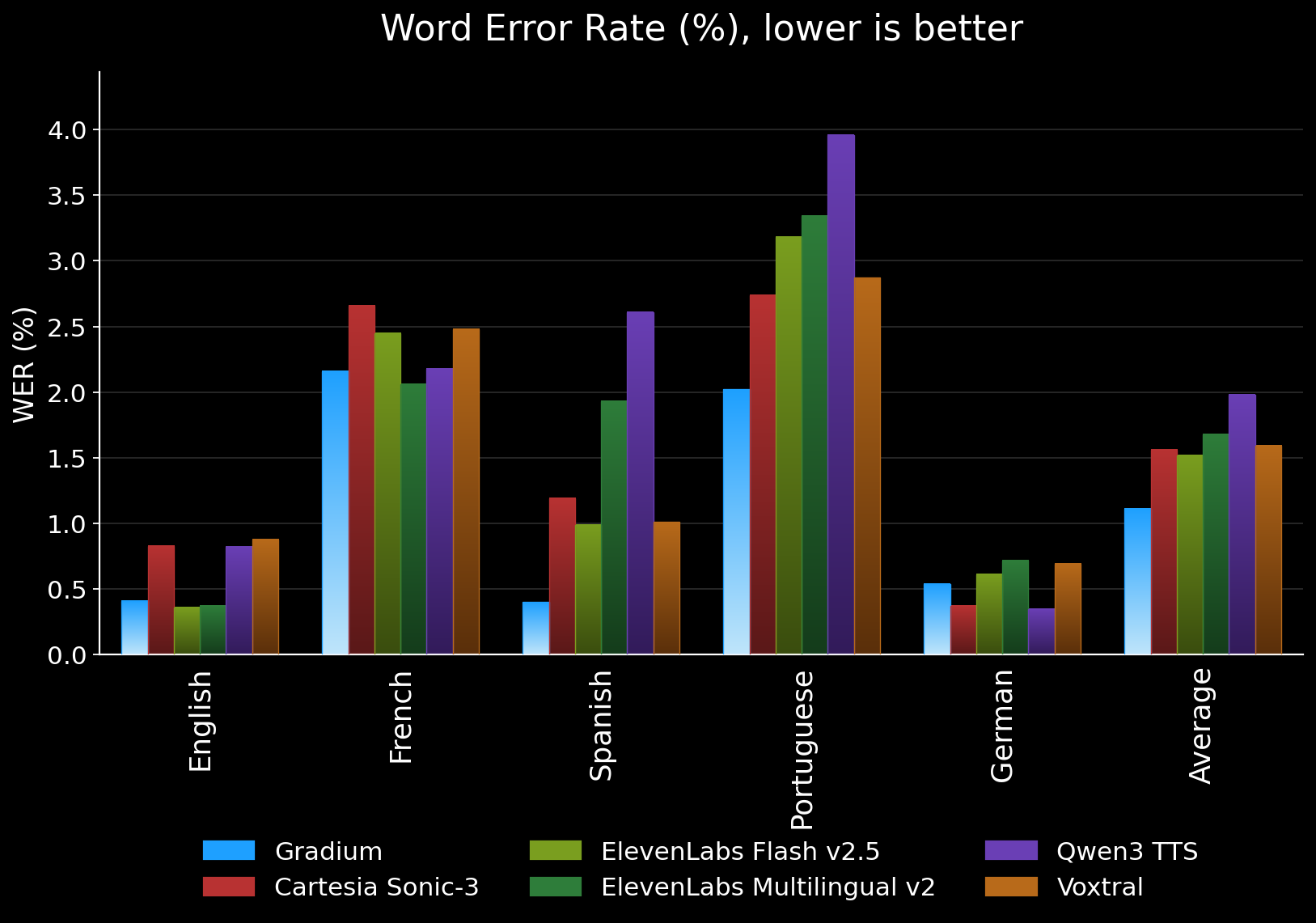
| Model | avg | en | fr | es | pt | de |
|---|---|---|---|---|---|---|
| Gradium | 1.11 | 0.41 | 2.16 | 0.40 | 2.02 | 0.54 |
| Cartesia Sonic-3 | 1.56 | 0.83 | 2.66 | 1.19 | 2.74 | 0.37 |
| ElevenLabs Flash v2.5 | 1.52 | 0.36 | 2.45 | 0.99 | 3.18 | 0.61 |
| ElevenLabs Multilingual v2 | 1.68 | 0.37 | 2.06 | 1.93 | 3.34 | 0.72 |
| Qwen3 TTS | 1.98 | 0.82 | 2.18 | 2.61 | 3.96 | 0.35 |
| Voxtral | 1.59 | 0.88 | 2.48 | 1.01 | 2.87 | 0.69 |
Gradium is best on Spanish and Portuguese, second on English (a hairline behind ElevenLabs Flash v2.5) and on French (behind ElevenLabs Multilingual v2), and mid-pack on German where the cluster of top systems is within 0.2 points of each other.
What's next
The MiniMax Multilingual set is the standard, and being on the standard matters: but it is not a hard test. It does not stress long numbers, serials, spelled-out content, or named entities, which is exactly where TTS systems tend to fall over in real product use.
More importantly, when we manually inspect the residual errors on this benchmark, almost all of them fall into one of three buckets:
- ASR errors: the synthesized audio is correct, but Qwen3-ASR mistranscribed it.
- Reference issues: typos or grammar mistakes in the original text content of the benchmark itself.
- Normalization gaps: the TTS and the reference are saying the same thing, but the normalizer didn't fold them together.
Very few of the remaining errors are actual TTS mistakes. That tells us the metric has saturated for the easy cases, and that meaningful progress now requires harder benchmarks: content that exercises numbers, entities, and code-switching: and complementary measures of robustness that are less hostage to ASR and normalizer quality.
That's where we're focusing next.
Beyond Word Error Rate
This post focused on WER because it's the most widely reported measure of text-to-speech pronunciation accuracy and the easiest to compare across providers. But WER alone doesn't make a production-ready TTS system. Real voice agents also need low time to first audio, natural-sounding voices, robust handling of numbers, named entities, and code-switching, and predictable behavior under streaming and interruption. Gradium is designed to deliver across all of those dimensions, not just top a single multilingual accuracy table.
If you're building a voice agent and want to talk through TTS evaluation, pronunciation accuracy, or how Gradium fits into your stack, we'd love to hear from you. Reach out at contact@gradium.ai or visit gradium.ai.