Launching Gradium Translate: the best accuracy-latency tradeoff against gemini-3.5-live-translate and gpt-realtime-translate
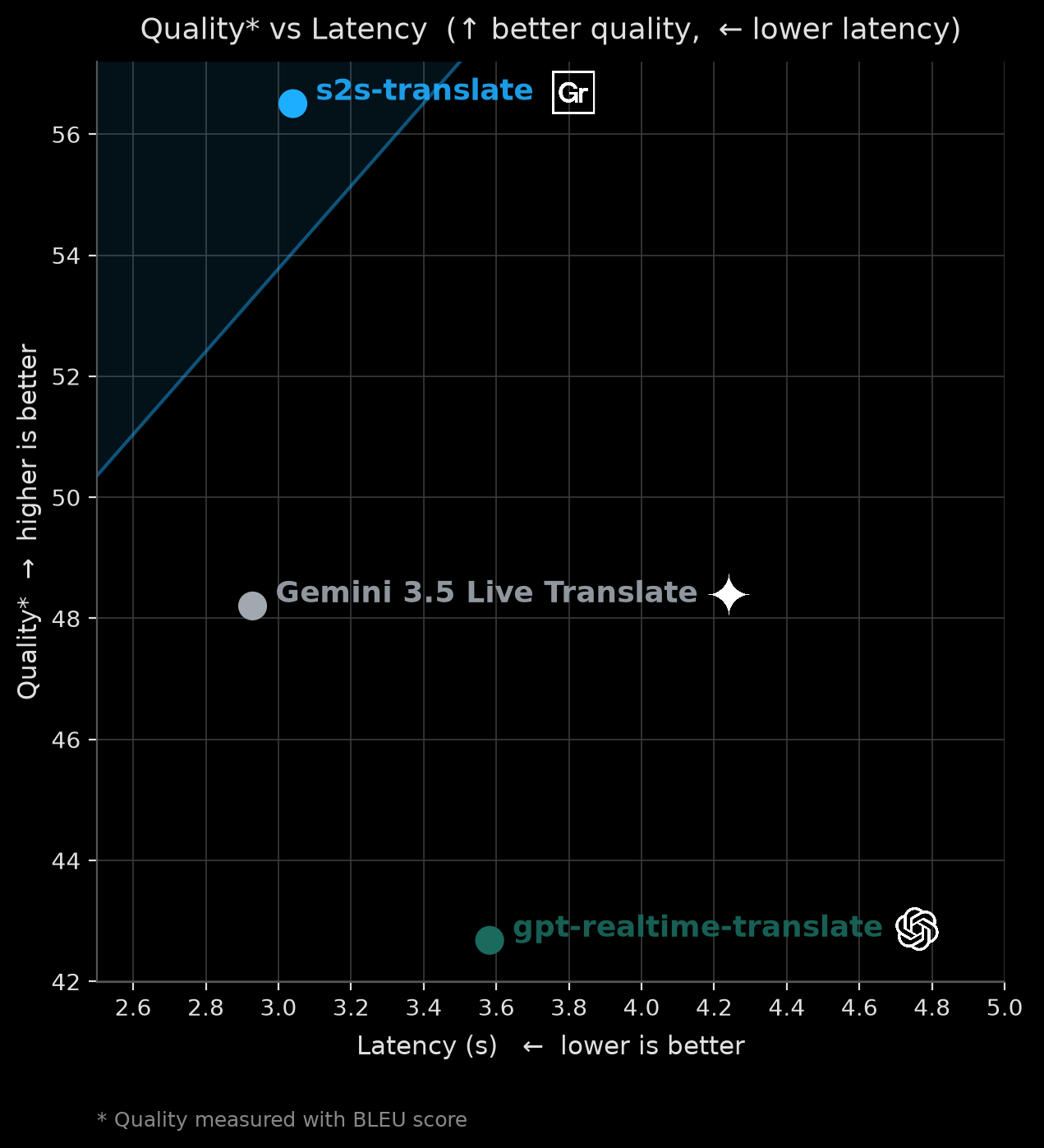
BLEU vs. latency across all languages: Gradium (s2s-translate) versus gemini-3.5-live-translate and gpt-realtime-translate.
Today we are launching two models: stt-translate and s2s-translate. stt-translate collapses transcription and translation into a single step, so you speak in one language and it returns text in another directly, with no intermediate transcript to wait on. s2s-translate builds on it for a complete Speech-To-Speech experience: speech in one language goes in, and natural speech in another comes out. Together they replace the usual three-model cascade (Speech-To-Text, Text-To-Text translation, Text-To-Speech) and deliver the combination of highest accuracy and lowest latency, with the ability to choose the target voice for the generated speech, including a clone of your own.
This post covers what stt-translate does, how we measure its quality, how s2s-translate pairs it with our TTS models for a full Speech-To-Speech workflow, and how both compare with gpt-realtime-translate and gemini-3.5-live-translate.
Real-time speech translation with Gradium s2s-translate.
What stt-translate does
stt-translate takes speech in any of five languages and returns translated text in any of the same five languages: English (EN), French (FR), German (DE), Spanish (ES), and Portuguese (PT). Any source language maps to any target language across that set, in any direction, for 20 language pairs in total.
Inspired by the Hibiki-Zero framework for learning real-time speech translation (Labiausse et al.: arxiv.org/abs/2602.11072), we build a model that optimizes low latency and high accuracy jointly through Reinforcement Learning. Because translation happens inside the speech model rather than in a separate text stage downstream, there is no intermediate transcript to wait on and no handoff between systems. You can try it live on the translation page.
What s2s-translate does
s2s-translate turns spoken audio in one language into spoken audio in another, end-to-end. It builds on stt-translate by pairing it with a Gradium TTS model in a single service: source speech is translated directly to target-language text by stt-translate, and that text is spoken by the TTS model. You stream audio in over a WebSocket and receive both the synthesized output audio and the translated transcript back as they are produced, so there is no need to wire STT and TTS together yourself or manage two connections.
You choose the output voice with a required voice_id in the target language. That voice can be any voice from our catalogue, or a clone of your own, so the translated speech keeps the speaker identity you want.
How we measure quality: BLEU and MetricX
Translation quality is not a single number, so we report two complementary metrics.
BLEU (Bilingual Evaluation Understudy) is the long-standing standard for machine translation (Papineni et al.: aclanthology.org/P02-1040.pdf). It compares the model's output against one or more human reference translations by measuring n-gram overlap, the proportion of single words, word pairs, triples, and longer sequences that appear in both the output and the reference. It applies a brevity penalty so that short outputs cannot inflate the score. BLEU runs from 0 to 100, where higher is better. Its strength is that it is fast, reproducible, and comparable across systems. Its limitation is that it rewards surface-level word matching and can penalize a correct translation that happens to use different wording than the reference.
MetricX is a learned, neural translation-quality metric developed by Google (Juraska et al.: aclanthology.org/2024.wmt-1.35.pdf). Rather than counting n-gram overlap, it uses a model fine-tuned on human quality judgments to predict how a human would rate a translation. MetricX is reported as an error score, so lower is better, and it correlates more closely with human assessment than BLEU does, particularly for meaning preservation and fluency where two valid translations differ in phrasing. We report it alongside BLEU because the two metrics catch different failure modes: BLEU for lexical fidelity, MetricX for semantic adequacy. For clarity, in the charts below we plot 25 − MetricX so that higher is better, letting the MetricX bars read in the same direction as BLEU.
Benchmarking translation accuracy against gemini-3.5-live-translate and gpt-realtime-translate
For this benchmark we use a proprietary dataset of conversational speech, representative of typical daily conversations between people across a broad range of everyday topics, from holidays and work to travel and the weather. We chose it specifically because it is conversational and reflects typical real-world use cases for translation, rather than scripted or read-aloud text. That makes the scores below a closer proxy for how the models actually perform in practice. We benchmark stt-translate against the strongest real-time translation systems available, gpt-realtime-translate and gemini-3.5-live-translate, on the same audio.
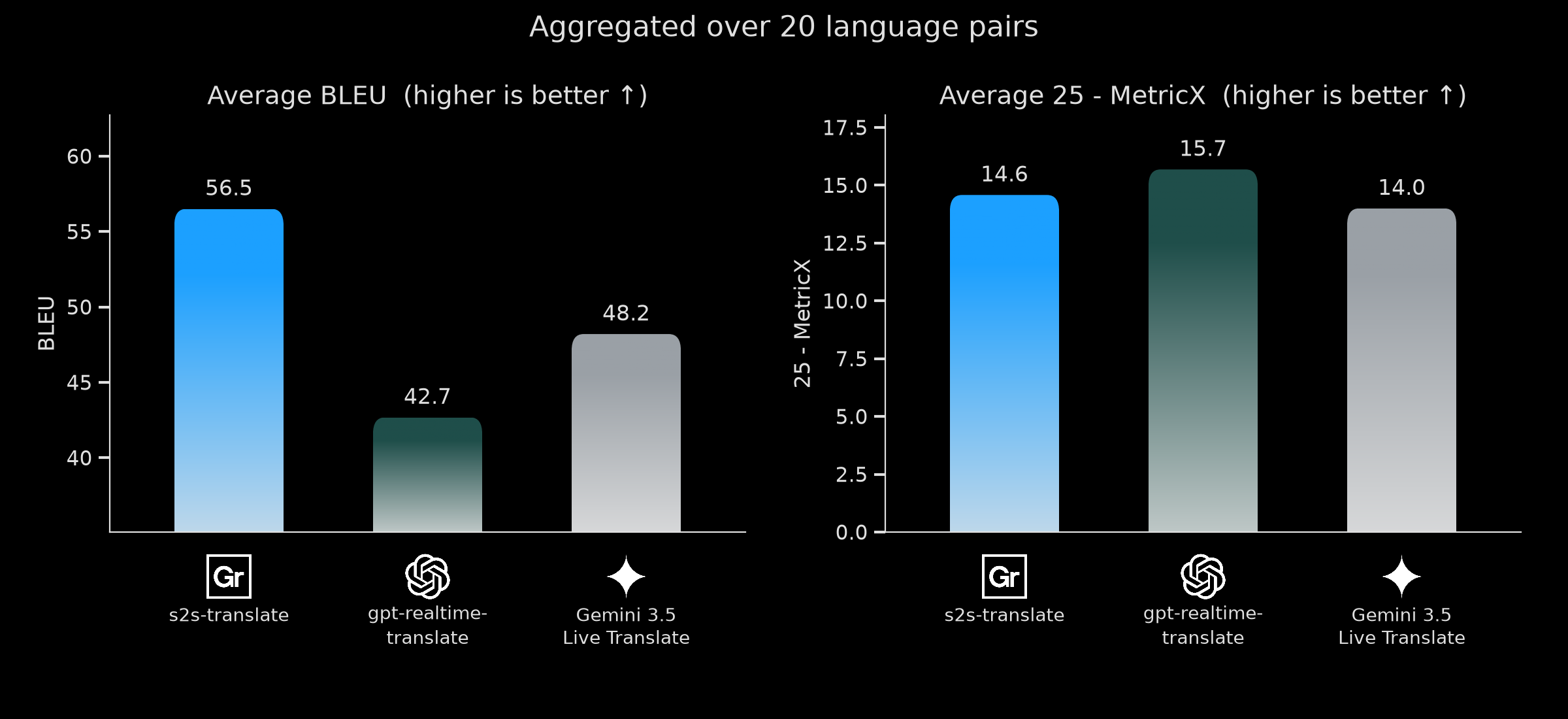
Average BLEU and 25-MetricX aggregated over all languages.
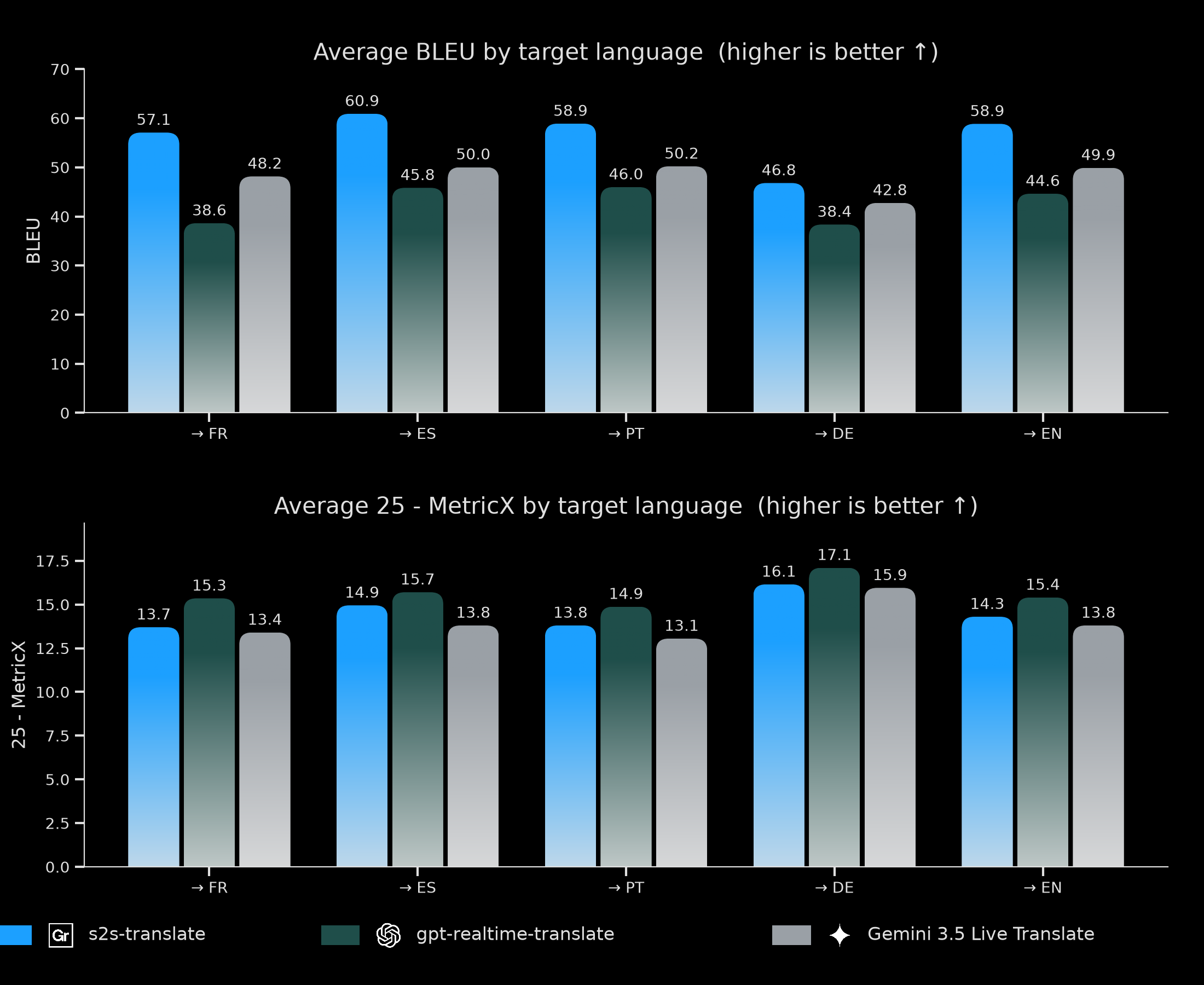
Average BLEU and 25-MetricX by target language across → FR, → ES, → PT, → DE, → EN.
Compared to gemini-3.5-live-translate, Gradium is more accurate overall, leading on both BLEU and MetricX, which means a more accurate translation. Compared to gpt-realtime-translate, Gradium leads on BLEU and is comparable on MetricX.
Voice features with Gradium Speech-To-Speech
The output voice is a first-class part of s2s-translate: you select the voice for the synthesized speech with a required voice_id in the target language, and that voice can be any of the voices in our catalogue. You can also clone your own voice and translate into it, so a speaker can be heard in another language while still sounding like themselves.
This is where s2s-translate pulls ahead of the alternatives. gpt-realtime-translate gives you no control here: you cannot choose the target voice and you cannot clone your own, even though both are typically essential for dubbing, localization, and voice agents. With s2s-translate you keep full control over who the translated speech sounds like.
Underneath, s2s-translate runs the whole pipeline for you over a single duplex WebSocket: you stream audio in and receive the synthesized audio and translated transcript back as they are produced, with no need to wire STT and TTS together or manage two connections. That two-model design is also faster than the cascaded solutions on the market, which is a direct consequence of the architecture below.
Latency
The standard Speech-To-Speech translation stack is made of three models: Speech-To-Text, then Text-To-Text translation, then Text-To-Speech. Each stage is a separate inference call, each adds its own processing time, and each introduces a handoff that the next stage has to wait on before it can begin.
Our workflow uses two. stt-translate performs transcription and translation in a single pass, so the dedicated Text-To-Text translation stage disappears entirely. This removes one full model from the critical path, along with its inference latency and its handoff. With one fewer stage to traverse, the end-to-end path from input speech to translated output is shorter than any three-model cascade can achieve at equivalent quality.
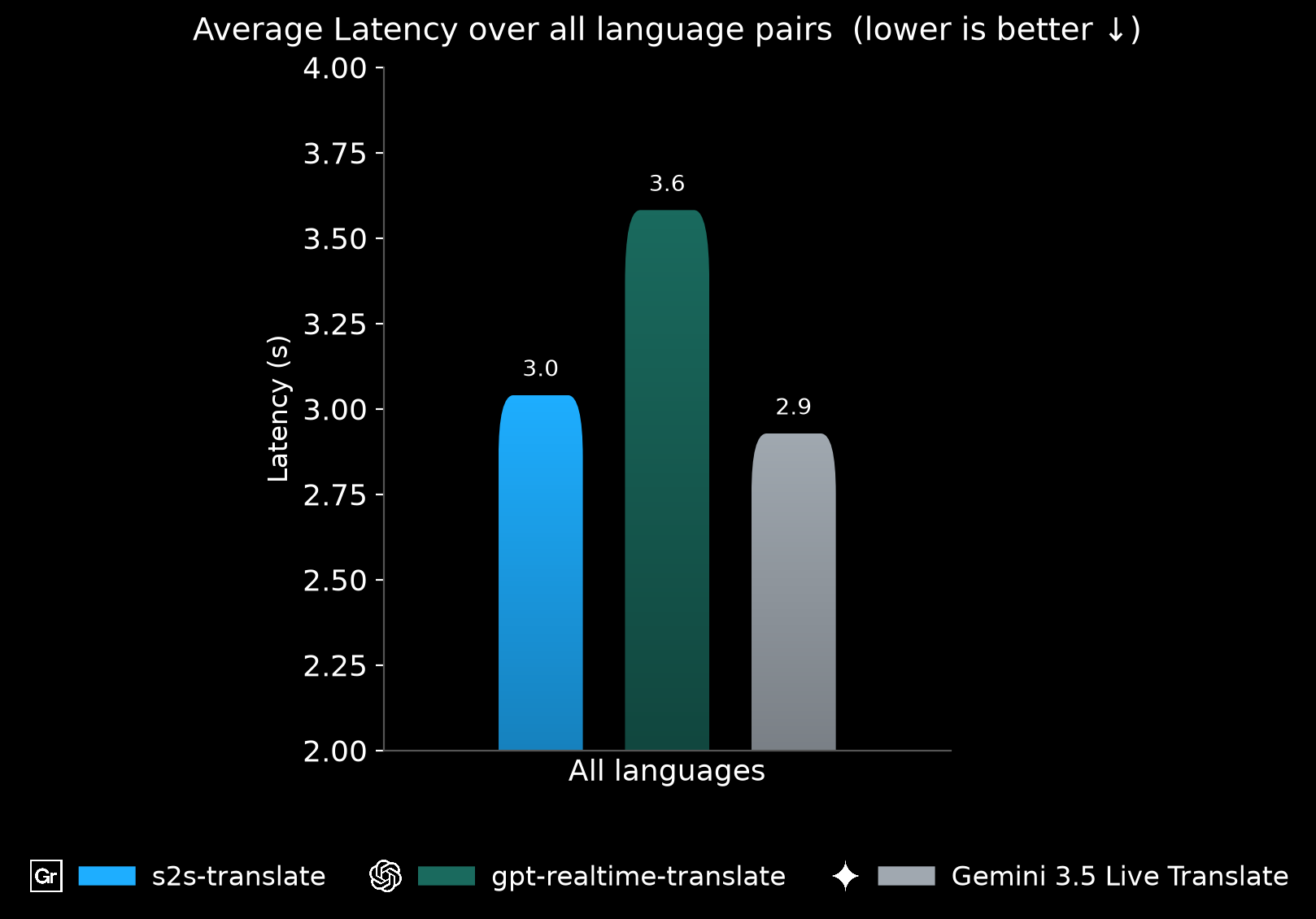
Average latency over all language pairs (lower is better): Gradium s2s-translate (3.0s) and gemini-3.5-live-translate (2.9s) are well ahead of gpt-realtime-translate (3.6s).
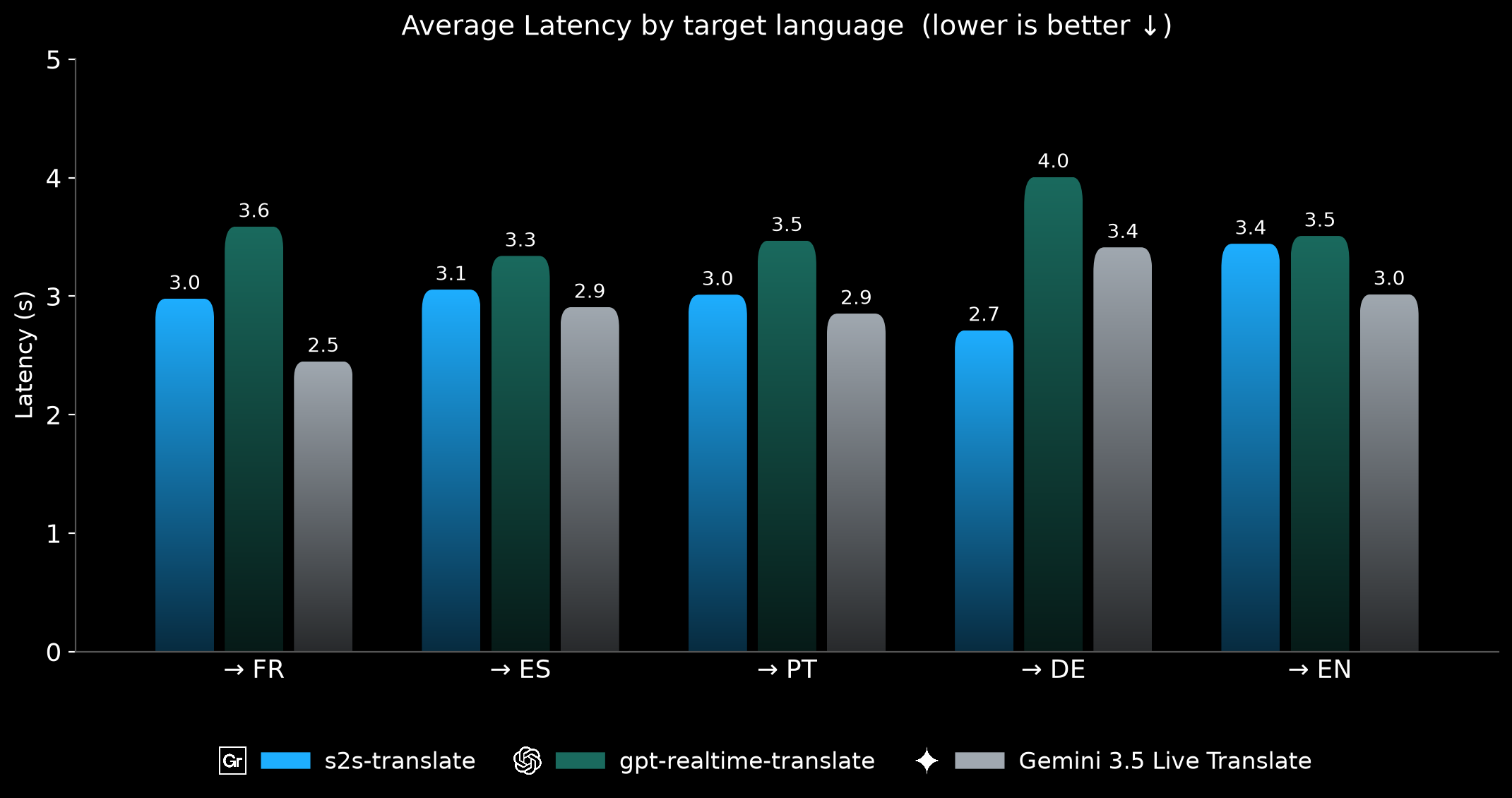
Average latency by target language (lower is better).
Get started
Both stt-translate and s2s-translate are available now. You can try real-time translation directly in the browser on the translation page: gradium.ai/translate. stt-translate returns translated text from your speech, and s2s-translate returns natural speech in the target language and voice of your choice, including a clone of your own. For integration details on both models, see the API docs.
Want a language that is not in the current set of five? Reach out and tell us which languages to add to the batch. Questions or feedback? Reach us through the contact page.